【ASC】Openmp学习笔记
本文最后更新于:3 个月前
OpenMP是用于共享内存并行系统的多线程程序设计的一套指导性注释。OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了这两方面的部分工作,提高程序员们的开发效率。
作为高层抽象,OpenMP并不适合需要复杂的线程间同步和互斥的场合,不能在非共享内存系统上使用。
简单来说,就是把一件事放在多个核心上去做。

1 | |
parallel computing
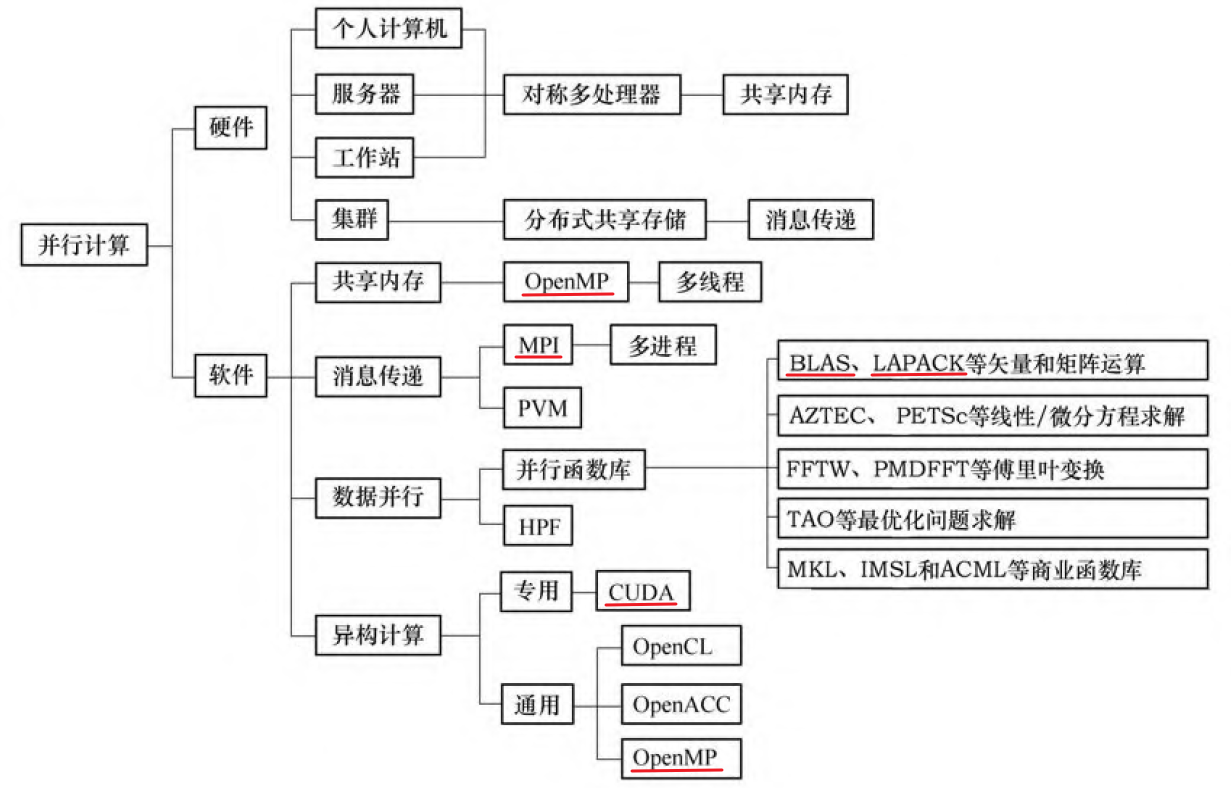
并行计算机种类
通常, 编程人员需要对现有的串行程序进行修改, 对CPU 之间、CPU与GPU 之间的通信和控制进行协调从而解决并行程序所带来的数据竞争、同步等潜在问题, 实现并行程序的高稳定性和高并行加速比。
当多颗CPU 对同一地址的内存单元进行读写操作时, 会出现访问冲突, 即数据竞争。
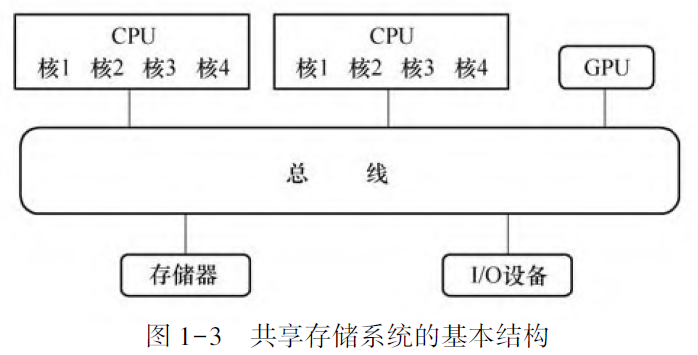
并行计算机通常可分为四大部件: CPU、GPU、存储器和网络。
从硬件设计上来讲, CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU 则由数以千计的更小、更高效的核心组成, 这些核心专为同时处理多任务而设计。
根据存储器与CPU 的连接方式可分为共享存储系统和分布存储系统。
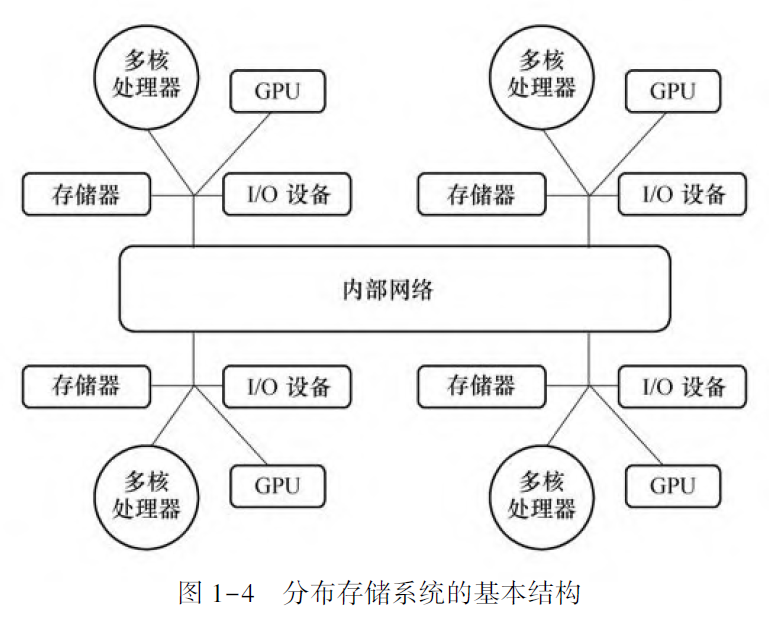
根据数据通信方式,分为共享地址空间系统和消息传递系统。
常见并行硬件系统:
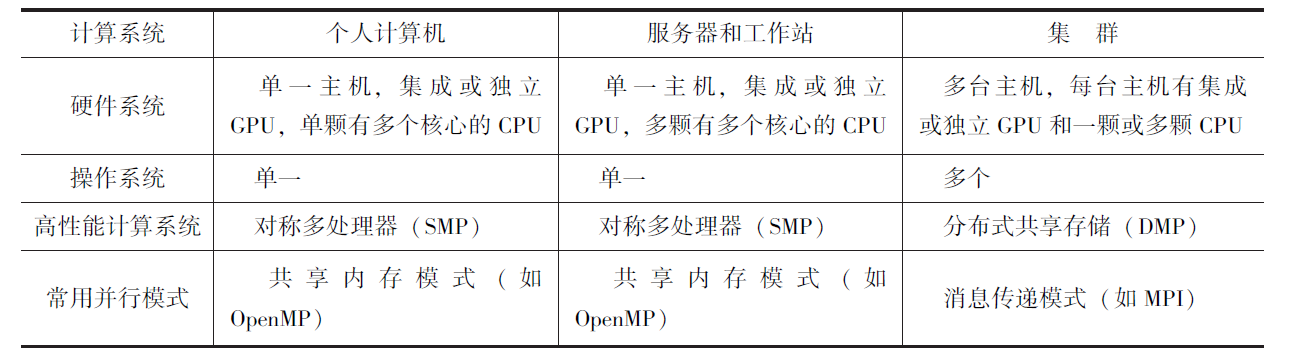
多指令多数据流系统(Multiple Instruction Stream Multiple Data Stream, MIMD), 是指每颗CPU 上执行的指令和处理的数据各不相同。目前常见的多核个人计算机和集群计算机可归为此类。
并行计算
Parallel Computing
High Performance Computing
Supercomputing
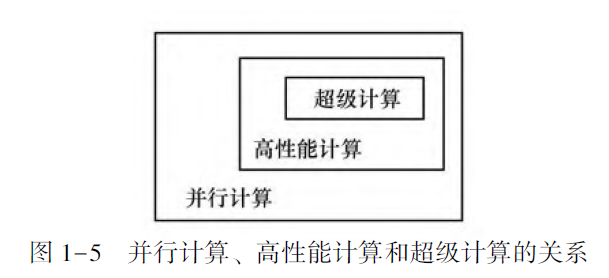
并行计算的重要特征是短的执行时间和高的可靠性, 它主要是指以高精度浮点运算为主的科学计算。在计算任务中存在多核心并行即可视为并行计算。实质是将一个待求解的问题分解成若干个子问题, 各个子问题均由独立的CPU 同时进行计算。
高性能计算要求针对所使用的硬件环境(多核和GPU), 通过向量化、提高Cache(缓存) 命中率、采用多核心同时执行计算任务。
超算(超级计算) 指在少量节点的高性能计算性能不足以满足实验计算量和运算规模需要, 而必须在超级计算机或巨型机上解决的大型、复杂运算。
并行处理技术的三种形式:
- 时间并行,使用流水技术
- 空间并行
- 时间和空间的同时并行
高性能并行计算特征
- 正确性:并行计算结果与串行计算结果的比较是并行编程中的重要一环。
- 高性能:并行加速比和并行效率
- 可拓展性:不要因为新硬件的出现而不得不大幅度地修改并行程序
并行编程模式
按通信方法可分为共享内存模式、消息传递模式、数据并行模式和异构计算模式。
工程技术人员常用的并行编程模式是消息传递接口(Message Passing Interface,MPI) 和直接控制共享内存式并行编程的应用程序接口( Open Multi - Processing,OpenMP)。
共享内存模式
共享内存存储, 是指多颗CPU 都访问一个共享存储器。
在共享内存模型中, 一个并行程序由多个共享内存的并行任务组成, 数据的交换通过隐式地使用共享数据(即线程间的通信通过对共享内存的读写操作) 来完成。在大多数情况下, 此编程模式的主要任务是对循环进行并行处理, 而计算与数据的划分和任务之间的通信则由编译器自动完成。
OpenMP 是一种基于数据并行的编程模式, 即将相同的操作同时作用于不同的数据,从而提高问题求解速度。
消息传递模式
消息传递模式是针对多地址空间进行的多进程异步并行模式。
在消息传递模式中, 一个并行程序是由多个并行任务组成, 并且每个并行任务拥有自己的数据并对其进行计算操作。
其基本特征是进程的显式同步、通过显式通信完成任务之间数据的交换、显式的数据映射和负载分配。
目前 广泛使用的消息传递模式有两种: 并行虚拟机(Parallel Virtual Machine, PVM) 和消息传递界面 。
MPI 是为开发基于消息传递模式的并行程序而制定的工业标准, 其目的是为了提高并行程序的可移植性和扩展性以及较高的并行效率。
目前几乎所有的高性能计算系统都支持PVM 和MPI。
任务的粒度= 执行时间/任务通信时间
常用概念
并行(Concurrent)是指两个或者多个事件在同一时刻发生; 而并发(Parallel)是指两个或多个事件在同一时间间隔内发生。
并发性, 又称共行性, 是指在同一个CPU 上能处理多个同时性(不是真正的同时,而是看来是同时, 因为CPU 要在多个程序间切换) 程序的能力; 并发的实质是物理CPU在若干程序之间多路复用, 并发性是对有限物理资源强制行使多用户共享以提高效率。
在多个程序环境下, 并行性使多个程序同一时刻可在不同CPU 上同时执行。当一个CPU 执行一个线程时, 另一个CPU 可以执行另一个线程, 两个线程互不抢占CPU 资源, 可以同时进行。这种执行方式被称为并行。
并发执行、并行执行、并行计算:
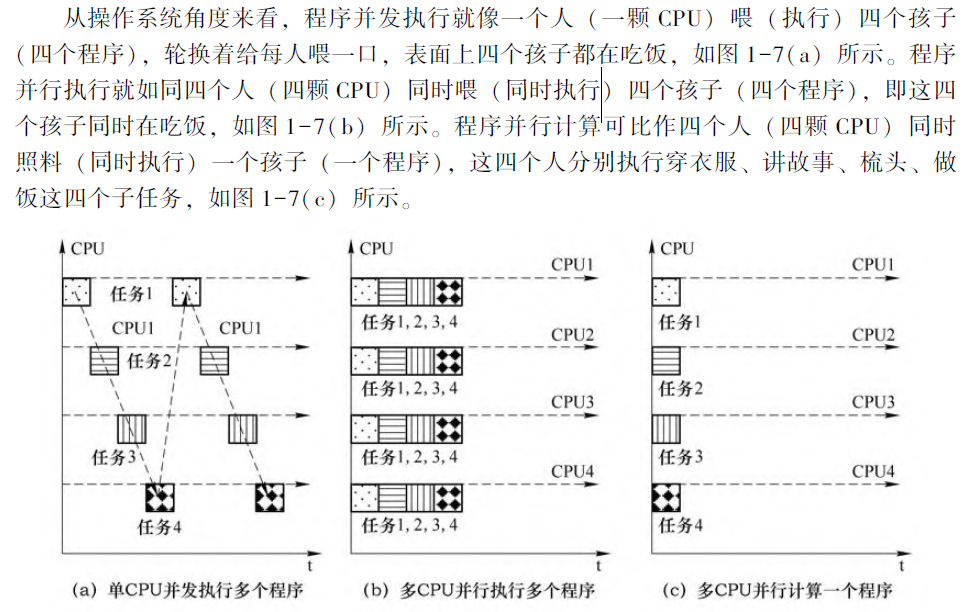
线程绑定是将线程绑定在固定的处理器上, 从而在线程与处理器之间建立一对一的映射关系。如果不进行线程绑定,线程可能在不同的时间片运行在不同的处理器上。
加速比的定义是顺序程序执行时间除以计算同一结果的并行程序的执行时间。
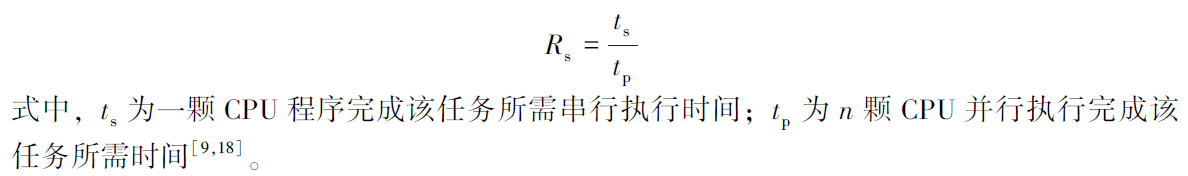
相对加速比是在使用相同算法情况下单颗CPU 完成该任务所需时间除以n 颗CPU 完成该任务所需时间。
实际加速比是指用运行速度最快的串行算法完成该任务所需时间除以n 颗CPU 完成该任务所需时间。
相对加速比是在使用相同算法情况下单颗CPU 完成该任务所需时间除以n 颗CPU 完成该任务所需时间。
实际加速比是指用运行速度最快的串行算法完成该任务所需时间除以n 颗CPU 完成该任务所需时间。
并行效率表示的是多颗CPU 在进行并行计算时单颗CPU 的平均加速比。
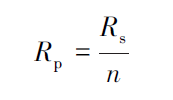
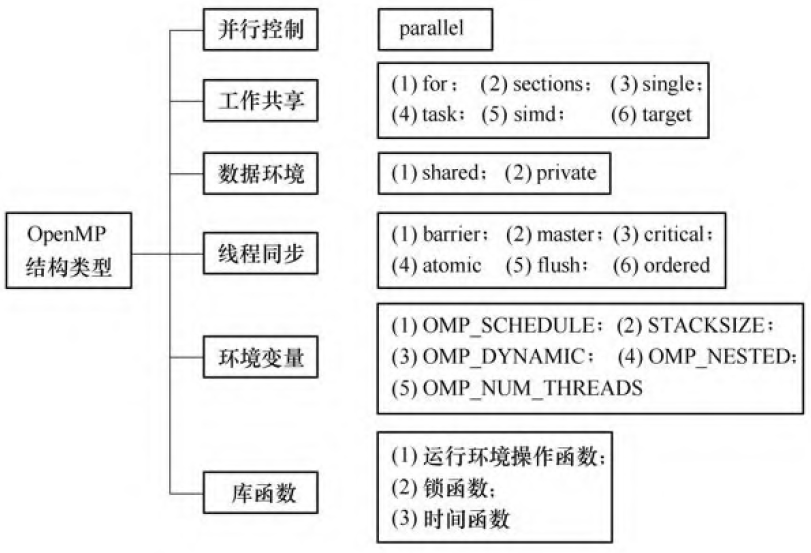
openmp
并行控制类型用来设置并行区域创建线程组, 即产生多个线程来并行执行任务;
工作共享类型将任务分配给各线程或进行向量化,工作共享指令不能产生新的线程, 因此必须位于并行域中;
数据环境类型负责并行域内的变量属性(共享或私有)、边界上(串行域与并行域)、主机和异构计算设备间的数据传递;
线程同步类型利用互斥锁和事件通知的机制来控制线程的执行顺序, 保证执行结果的确定性;
库函数和环境变量则是用来设置和获取执行环境相关的信息。
并行执行模式:
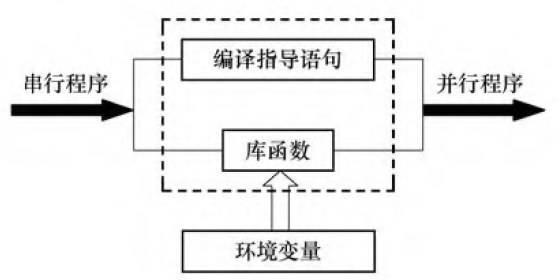
以omp_set_开头的函数只能在并行区域外调用, 其他函数可在并行区域和串行区域使用。
1 | |
Private() function sets tid & mcpu as private variables, ensuring the absence of influence between tids in each thread.
data env
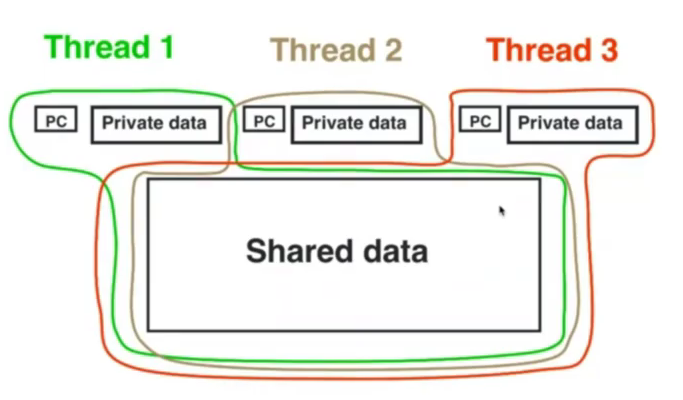
OpenMP 程序的一个重要特征是内存空间共享, 即多个线程通过任意使用这个共享空间上的变量而完成线程间的数据传递。
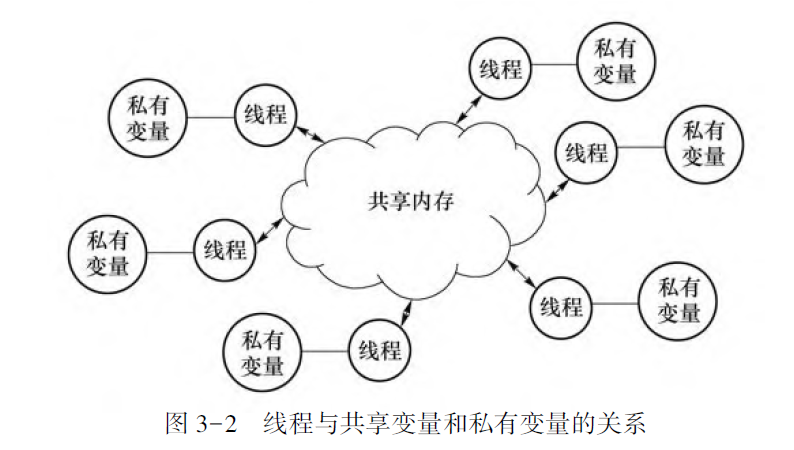
private
1 | |
在并行区域的开始处为线程组的每个线程产生一个该变量的私有副本;
其初始值在并行区域的入口处是未定义的, 它不会继承并行区域外同名原始变量的值。
shared
1 | |
将变量列表中一个或多个变量声明为线程组中子线程共享的变量。
所有线程对共享变量的访问即是对同一地址的访问,不要轻易使用。
在并行区域内定义的变量(非堆分配) 是私有变量;
没有特别用子句指定的, 在并行区域前定义的变量是共享的;
在堆(用new 或malloc 函数分配的) 上分配的变量是共享的, 但是指向这块堆内存的指针可能是私有的;
在指令for作用下的循环指标变量是私有变量。
firstprivate
1 | |
将其变量属性定义为私有变量; 并在进入并行区域时(或者在每个线程创建私有变量副本变量时),此子句会将每个线程的私有量副本的值初始化为进入并行区域前串行区内同名的原始变量的值。
lastprivate
将并行区域的最终结果复制并传递给并行区域外同名的原始变量。
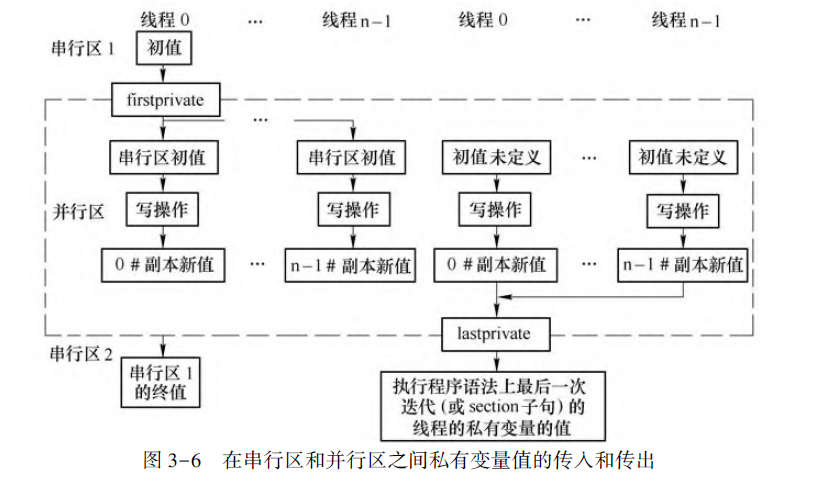
private不能和firstprivate、lastprivate混用同一个变量。
firstprivate和lastprivate可以对同一变量使用。
threadprivate
将全局变量指定为私有,设定threadprivate(x),只有并行区域第一个子线程0才会继承x的初值,其余子进程中的值x会被当作私有化变量,并且会被继承到下一个并行区中对应的子线程。
最终在串行区中的x值取决于上一个并行区中子线程0的最终x值。
copyin
主线程中threadprivate 声明的全局变量的私有副本复制给并行区域内各个线程的相应全局变量的私有副本。
这样, 线程组中所有线程各自拥有的全局变量的私有副本具有相同的值, 从而方便各线程访问主线程中的值。
copyprivate
将线程私有变量的副本的值从一个线程广播到本并行区域的其他线程的同名变量。
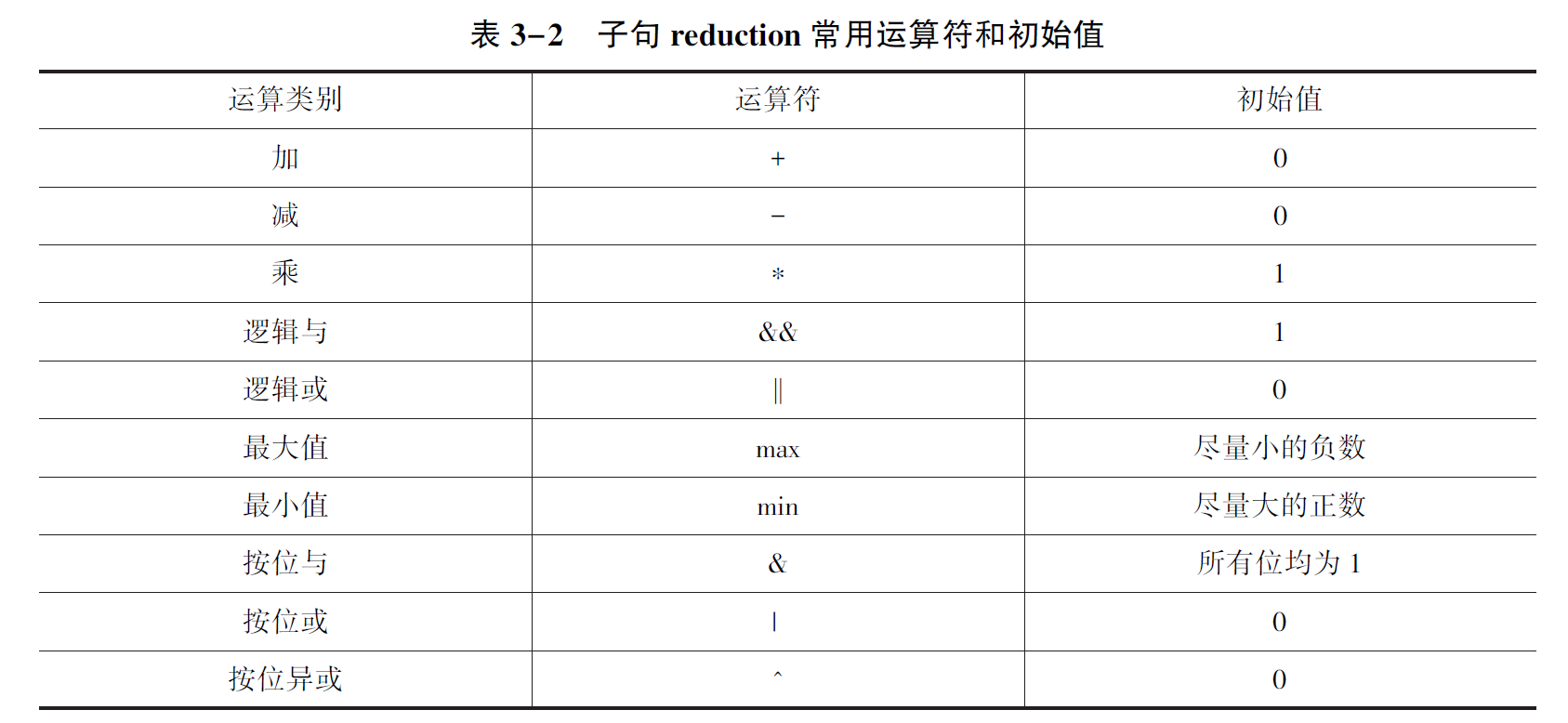
reduction
在科学运算中, 经常会遇到累加求和、累减求差、累乘求积、逻辑操作等运算操作。
这类运算的特点是反复地将运算符(例如, 加法或求最小值) 作用在一个变量或一个值上, 并把结果保存在原变量中。
这类操作被称为规约操作。
reduction(运算符:变量列表)就是对前后具有依赖性的循环进行规约操作的并行化。
1 | |
- reduction子句中的变量列表定义为私有变量,且各子线程对该私有变量副本依据运算符进行初始化
- 各子线程依据规约进行计算,不断更新各自子线程的私有变量副本
- 并行结束后,各子线程的私有变量副本依据规约对原始变量进行更新并将原始变量带出并行区域
数据竞争
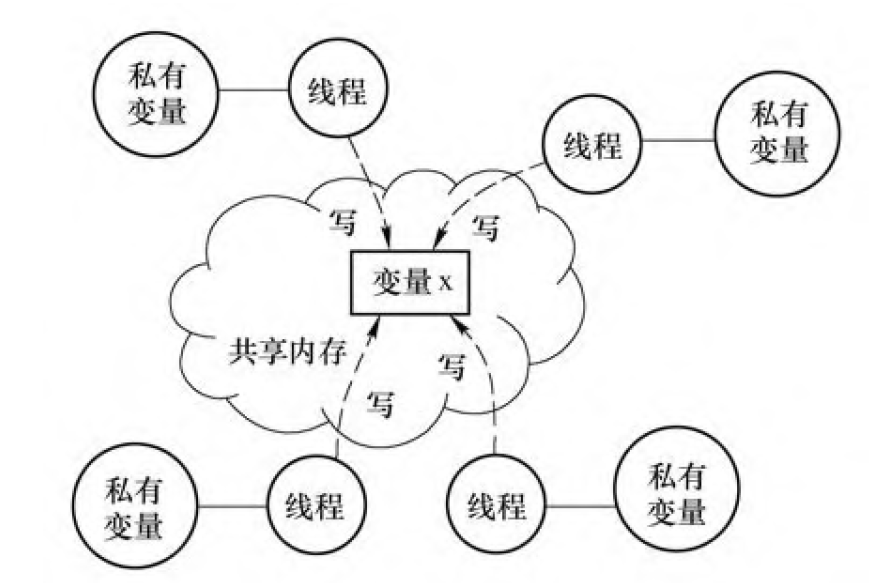
数据竞争的产生一般可归结为如下因素:
(1) 两个或两个以上的线程访问同一个变量。
(2) 线程之间没有同步机制, 不拥有锁, 或者其中一个线程要执行写操作。
并行控制

指令parallel
1 | |
num_threads:设置线程组内线程的数量proc_bind:代表线程与处理器核心的映射关系参数
spread表示线程会尽量均匀地分布在各个核心上, 有利于实现内存带宽利用率的最大化;参数
close表示线程会尽量分布在相邻的处理器上, 有利于实现内存共享;参数
master表示所有线程都和主线程绑定在相同的位置(同一个处理器) 上。在大多数情况下, 参数spread能实现较好的性能。
函数omp_in_parallel()检测代码运行方式为串行或并行。
设置线程数量
默认情况:此方式要求实际参加并行的线程数量等于系统可以提供的线程数量。
调用环境库函数
omp_set_num_threads()【静态】omp_set_dynamic():动态设定各并行区域内线程数目【动态】- true:此时omp_set_num_threads()只能设定一个上限,实际参加并行的线程数不会超过所设置的线程数目
- false:此时omp_set_num_threads()设置的线程数目即为实际参加并
行的线程数
omp_get_dynamic():获取当前是否开启动态线程调整
指令num_thread()
环境变量OMP_NUM_THREADS
条件并行子句if
如果子句if的条件不能够得到满足, 就采用串行方式来运行并行区域内的代码;否则,使用并行方式。
子句if一般与parallel、parallel for、parallel sections配合使用。
并行构造
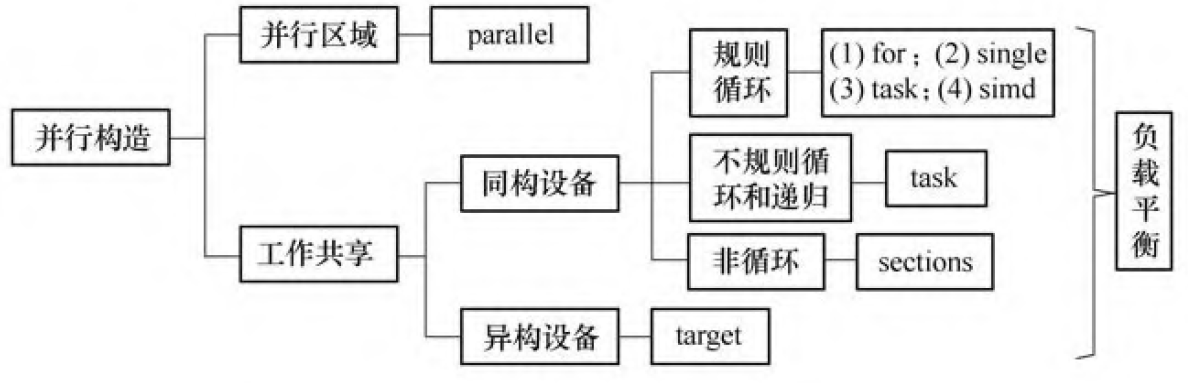
负载平衡
负载平衡是指各任务之间工作量的平均分配。
实现负载平衡的难点:
- 负载平衡的难题并不在于负载平衡的程度要达到多少
- 难度在于编程人员需要划分程序中的并行执行块
- 负载划分的误差会随着CPU核数的增加而放大
静态负载平衡:均衡分配。
动态负载平衡:在程序的执行过程中进行任务的动态分配。
动态负载平衡对任务的调度一般是由系统来实现的, 程序员通常只能选择动态平衡的调度策略, 不能修改调度策略。
依赖关系
循环依赖:如果一个循环存在循环依赖, 则需要在得到前一次迭代结果的前提下才能执行循环的下一次迭代。
指令for
1 | |
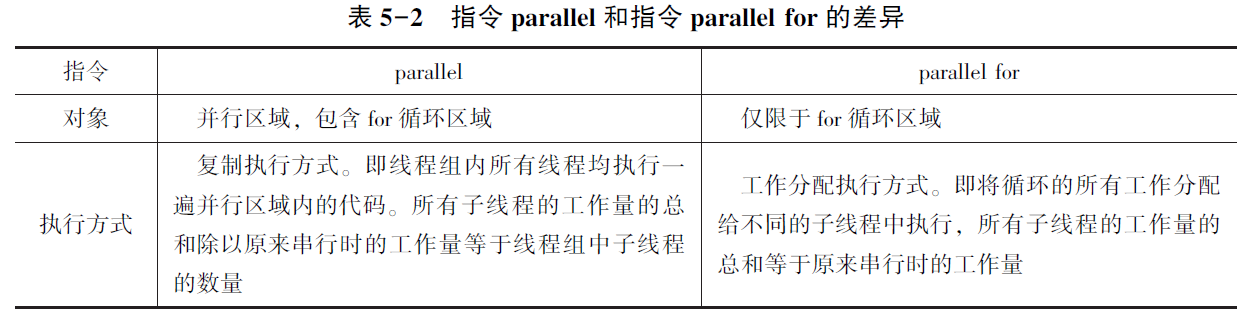
循环体任务调度:
schedule(static): 平均分配
schedule(dynamic, 10): 先到先得
schedule(guided, 10): 指数级下降
子句collapse
子句collapse只能用于一个嵌套循环。它是在不使用嵌套并行的情况下, 对多重循环进行并行执行。
具体而言, 子句collapse将一个多重层循环进行合并后展开为一个更大的循环, 从而增加将在线程组上进行划分调度的循环总数。
子句collapse(n) 是指将最邻近的n 层嵌套循环进行合并并展开为一个更大的循环。
指令sections
1 | |
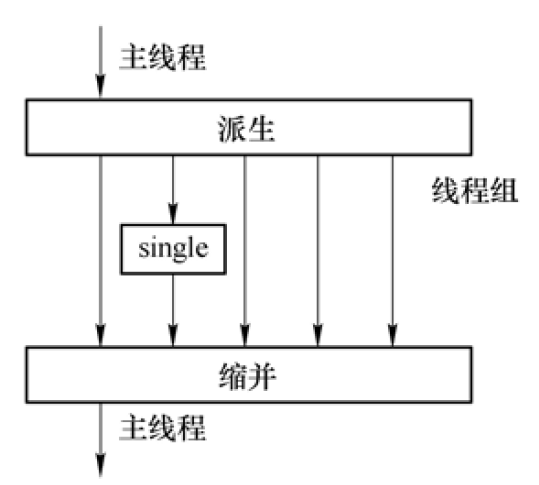
指令single
并行区执行串行代码。
具有隐含的barrier。
运行任意一个线程执行。
线程同步
同步:在时间上使各自执行计算的子线程之间必须相互等待从而保证各个线程的执行实现在时间上的一致性。
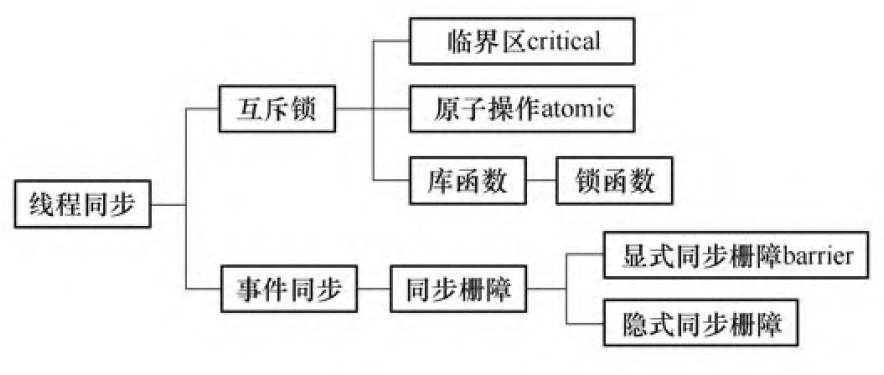
指令barrier
指令barrier 要求并行区域内所有线程在此处同步等待其他线程, 然后恢复并行执行barrier后面的语句。
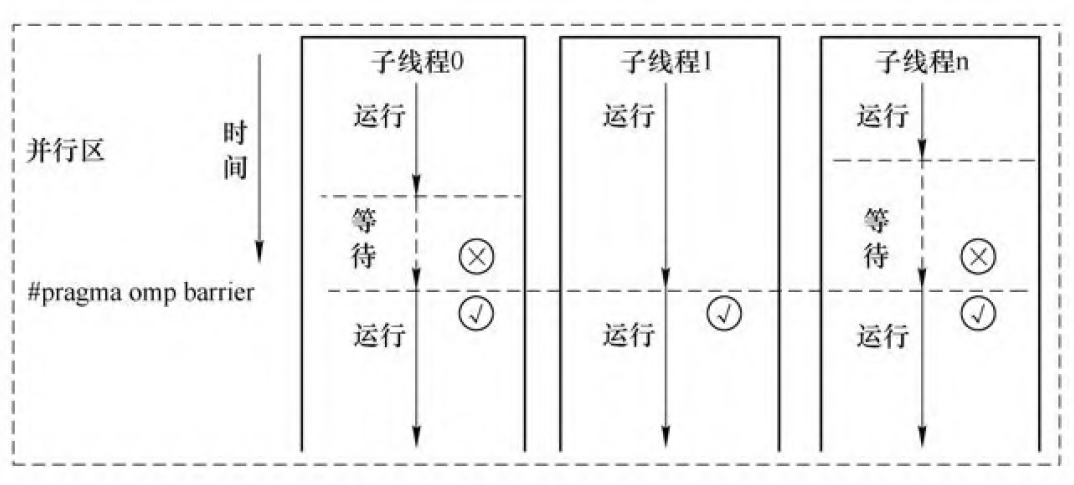
隐含的栅障要求: 每个线程在做完了自己的工作后必须在这里等待; 直到所有的线程都完成了各自的工作后, 所有的线程才能往下执行。【parallel for sections critical single】
使用nowait指令可以跨过barrier.
1 | |
指令nowait
去除#pragma omp for、#pragma omp sections、#pragma omp single中结构块结束处的隐含barrier.
1 | |
第二个for循环只有等待第一个for循环结束之后才能执行;
而第三个for循环并没有等待第二个for循环结束之后才开始执行。
指令master
指令master要求主线程去执行并行区域内的部分程序代码,而其他的线程则越过这段程序代码直接向下执行。
此条指令没有相关隐式栅障。